SPIN工具的安装与使用
# 1. 什么是Spin
Spin是一款广泛使用的开源软件验证工具,主要用于多线程软件应用的形式化验证。是一种用于分析分布式系统(特别是数据通信协议)的逻辑一致性的工具。 该工具使用Promela(Process or Protocol Meta Language)建模语言对系统进行建模。该语言允许动态创建并发进程。通过消息通道进行的通信可以定义为同步(即rendezvous)或异步(即buffered)。
# 2. Spin功能特性
- 旨在
有效验证多线程软件,而不是硬件电路的验证 - 支持使用
嵌入式C代码作为模型规范的一部分 - 支持使用
多核计算机进行并行的模型检验——支持安全性和活性属性的验证 - 采取
on-the-fly的工作方式,可以不用在验证系统属性之前预先构建全局状态图或Kripke结构,使得验证非常大的系统模型成为可能 - 可以用作
完整的LTL模型检验工具,支持用线性时序逻辑(LTL)表达的所有属性的验证,但它也可以用作基本的安全性(safety)和活性(liveness)属性的高效on-the-fly验证器 - 支持进程数量动态增加和缩小
- 支持
会合(rendezvous)和缓冲消息传递(buffered message passing),以及通过共享内存进行通信。还支持同时使用同步和异步通信的混合系统。 - 支持
随机、交互式和引导式模拟,以及基于深度优先搜索、广度优先搜索或有界上下文切换的穷尽和部分证明技术。该工具旨在很好地扩展到,并高效处理大规模问题。 - 该工具利用了
高效的偏序规约技术和(可选)类似 BDD 的状态存储技术来优化验证运行。
对一个设计进行验证时,需要使用Spin的输入语言PROMELA构建一个形式化的模型。PROMELA是一种非确定性语言,该语言基于Dijkstra的命令语言符号,并从Hoare的CSP语言中借用了I/O操作的相关符号。
# 3. Spin的四种主要使用模式
- 作为模拟器,允许通过随机、引导或交互式模拟进行快速原型设计
- 作为严格的验证工具,能够严格证明用户属性的正确性(使用偏序规约理论来优化搜索)
- 作为近似证明系统,可以验证非常大的系统模型,并具有最大状态空间覆盖范围
- 作为群验证(swarm verification,一种可以利用任意大小的云网络的新型群计算形式)的驱动引擎,可充分利用大量可用的计算内核来利用并行性和多样化搜索技术,从而增加在超大模型中的缺陷定位机会
# 4. Spin的下载安装
以在windows环境下为例:
# 4.1 Spin的下载安装
点击此处 (opens new window)下载pc_spin*.zip文件。从pc_spin*.zip中提取文件(若出现这种pc_spin*.zip文件则需要重命名为spin.exe)之后打开配置环境变量,将spin.exe所在的路径加入其中。
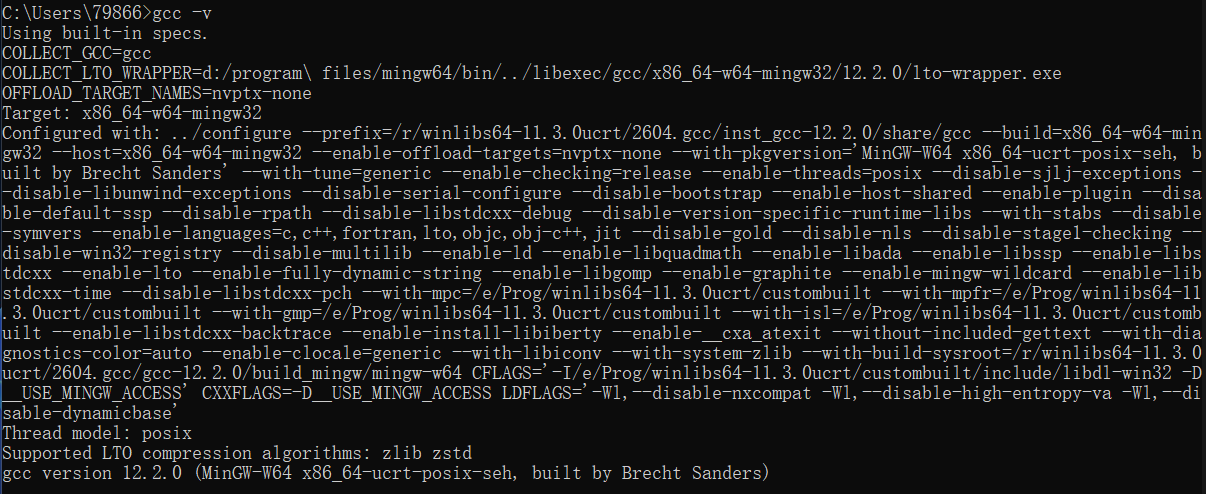
要运行Spin,也就是预编译版本,需要一个工作的C编译器和一个C预处理器,因为Spin将其模型检查软件生成为C源文件,这些文件需要在执行验证之前进行编译,故要确保已安装MinGW-w64。在命令行中输入gcc -v查询,出现下图反馈,说明gcc配置无误:
 下面使用
下面使用spin查看spin.exe是否添加成功,如果出现以下信息,则说明系统变量已成功添加:

# 4.2 iSpin的下载安装
iSpin是一个可选的,但强烈推荐的Spin的图形用户界面,用Tcl/Tk编写。要在PC上运行iSpin,需要Tcl/Tk的PC版本。点击此处 (opens new window)下载安装ActiveTcl,
然后双击spin安装目录下的ispin.exe即可打开:
# 4.3 iSpin的使用
新建一个plm文件,输入下列内容:
mtype = { ack, nak, err, next, accept };
proctype transfer(chan in,out, chin, chout)
{ byte o, i;
in?next(o);
do
:: chin?nak(i) ->
out!accept(i);
chout!ack(o)
:: chin?ack(i) ->
out!accept(i);
in?next(o);
chout!ack(o)
:: chin?err(i) ->
chout!nak(o)
od
}
init
{ chan AtoB = [1] of { mtype, byte };
chan BtoA = [1] of { mtype, byte };
chan Ain = [2] of { mtype, byte };
chan Bin = [2] of { mtype, byte };
chan Aout = [2] of { mtype, byte };
chan Bout = [2] of { mtype, byte };
atomic {
run transfer(Ain,Aout, AtoB,BtoA);
run transfer(Bin,Bout, BtoA,AtoB)
};
AtoB!err(0)
}
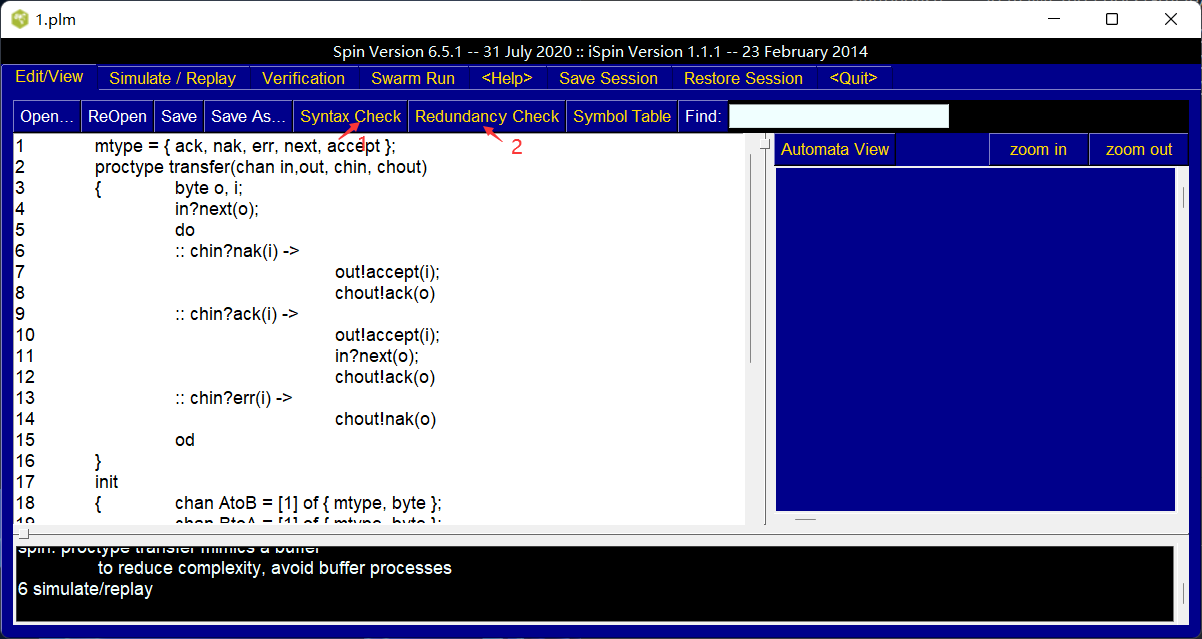
在iSpin中使用open打开该文件,通过在 Edit/view标签中的 Syntax Check,Redundancy Check之后:
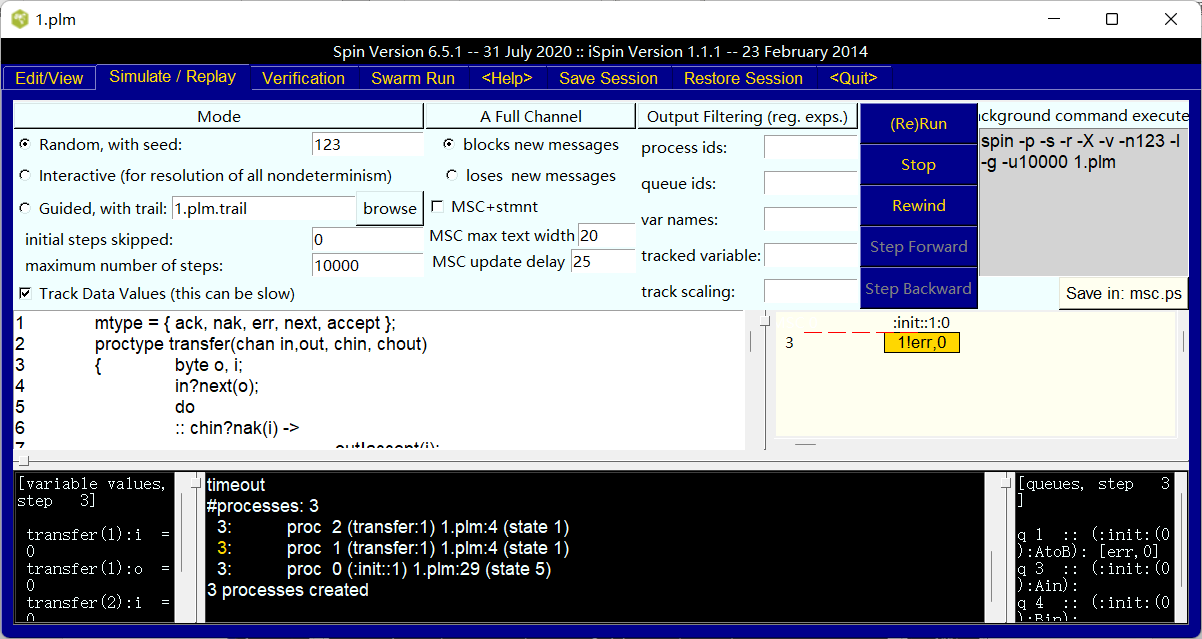
 通过 Simulate/Replay标签有(Re)Run, Stop 和 Rewind 等进行一个随机模拟的运行。其中中间左方白框为输入,左下方黑方框为变量数值,中间黑框是运行过程以及问题出错行:
通过 Simulate/Replay标签有(Re)Run, Stop 和 Rewind 等进行一个随机模拟的运行。其中中间左方白框为输入,左下方黑方框为变量数值,中间黑框是运行过程以及问题出错行:
# 5. 基于Promela的系统建模
Promela模型由3种类型的对象组成:进程、消息通道和变量。进程是全局对象。消息通道和变量可以声明为全局的或在进程内声明为本地的。 进程定义系统行为,消息通道和全局变量则定义进程运行的环境。
上面4.3就给出了一个promela的模型例子,该例子中定义了2个transfer进程,6个通道,每个进程中定义了2个byte类型的局部变量o和i。
# 5.1 进程
- 进程声明
形式:
proctype pname(chan In, Out; byte id )
{ statements }
上述进程定义了一个进程类型pname,该进程参数包含两个消息通道In和Out,以及一个byte类型的参数id。 注:在进程的声明中,相同类型的参数之间用“,”分隔,不同类型的参数之间用“;”分隔。进程体用一对{}括起来。
例:下面的代码声明了两个进程类型A和B
byte state = 2;
proctype A()
{ (state == 1) -> state = 3
}
proctype B()
{ state = state - 1
}
- 进程实例化
进程声明仅仅是定义了一个进程类型的行为,但并不能执行。要执行进程需要先通过进程实例化实例化出一个真实的进程,称其为进程定义。
在promela中通过run操作来实例化进程。
例:使用下面语句来将上面声明的两个进程类型实例化为真实的进程
run A();
run B();
每个进程实例都有一个唯一的实例编号,它由run操作符(和pid)产生。进程实例保持活跃状态,直到进程体结束。进程不能将数组作为形参类型,但允许使用结构体。
- 进程声明的扩充
进程声明可以通过多种方式进行扩充。最一般的形式是:
active [N] proctype pname(...) provided (E) priority M
其中,active [N] 表示在初始系统状态就定义N个proctype的进程实例。其中N是一个常数。如果[N]不存在,则仅激活一个实例。通过active修饰符激活的实例的形参初始化为0。一个proctype 可以有一个与之关联的启用条件E,它是一个通用的表达式,表达式中可能包含常量、全局变量、预定义变量timeout和pid。启用条件在初始状态下进行计算。为了在随机模拟过程中使用,进程实例可以以优先级M运行,M是一个>=1的常数。这样的进程被调度的可能性是默认(优先级 1)进程的M倍。
执行优先级也可以在run语句中使用:
run pname(...) priority M;
使用run语句实例化的进程的默认优先级是1。注:优先级对分析过程是没有影响的。
- 初始化进程
每个Promela模型都会显示地包含一个init进程,init进程主要用于初始化变量和执行适当的进程实例化来对系统进行初始化。init进程的定义方式:init { statements }
例如:
init
{
run A();
run B();
}
- Never claim
在promela中,使用never claims来描述不被期望或非法的行为,即希望永远不会发生的行为。Never claim的定义方式:never { statements }
是promela中一种特殊的进程,如果存在,则实例化一次。 Never claim被定义为系统状态的一系列命题或布尔表达式,这些命题或布尔表达式必须按照指定的顺序变为真,以匹配感兴趣的行为。在spin中,never claim可以手写,也可以通过转换工具将LTL 公式转换得到。
如果模型中存在never claim,则系统和该claim将同时执行,即在每一步中都是系统执行一步,never claim进程执行一步。如果claim自动机没有可执行的迁移了,则沿着该路径的搜索将停止,然后回溯到别的执行路径继续搜索。
statements中的语句被解释为条件,因此不应有副作用(尽管这将导致警告而不是语法错误)。因此,在never claim中不能使用赋值、自动递增和递减操作、通信、运行和断言语句等。在never claim中可以使用下面三个函数以获取相应的信息:
1. enabled(pid):如果进程pid能够执行操作,则此布尔函数返回true。该函数只能在不允许同步通信的系统中使用
2. pc_value(pid):该函数返回进程pid当前所处的状态编号。(使用-d选项可以看到状态编号。)
3. _np:如果系统处于非进度状态,则此谓词为真,否则为假。引入它是为了更有效地搜索非进度周期。
# 5.2 消息通道
- 消息通道的定义
消息通道主要用于不同进程之间的数据传输。消息通道可以为全局或局部通道。通道名字可以作为消息的一部分通过另一个通道从一个进程传送到另一个进程,也可以在进程实例化时作为其实参传递给进程。
消息通道定义的几种方式:
chan qname = [16] of { short }
chan transfer = [16] of { byte, int, chan, byte }
chan device = [0] of {byte};
chan channel;
chan chanArray[3] = [0] of { int }
在上述定义中:
- qname定义了一个最多可以存储16条消息的通道,消息类型在大括号之中定义,每条消息都是一个short类型的数据。
- transfer定义了一个最多可以存储16条消息的通道,其中每条消息都包含2个byte类型的数据、1个int类型的数据、以及一个通道名称。
- device通道最多可以存储的消息数量为0,表示该通道不能存储消息。称这类通道为无缓冲通道,或同步通道。对无缓冲通道,因为消息不能存储,因此发送和接收必须同步,即若一个进程往该通道中发送数据,则同时必须有另一个进程从通道中接收数据。
- Channel是一个未初始化的通道,只有在分配了一个初始化的通道后才能使用它。
- chanArray定义了一个包含3个通道的通道数组,每个通道都是传送1个int数据的无缓冲通道。
请注意,chan类型的对象可以是另一个通道中消息的一部分。给定一个通道qname,函数len(qname)返回该通道中现有的消息数量。
- 消息的发送与接收
- 消息的发送:
qname!expr,将expr表达式的值发送到通道qname中(一条消息发送操作只有在消息通道没有满的时候才是可执行的) - 消息的接收:
qname?msg,从通道qname的开头位置接收一条消息存在变量msg中(一条消息接收操作只有在消息通道不是空的时候才是可执行的) - 发送或接收多个数据:
qname!expr1,expr2,expr3
qname?var1,var2,var3
若发送或接收的数据数量与通道定义中声明的消息数据不一致,将产生错误。
在消息的发送和接收操作中,第一个消息字段通常用于指定消息类型(一个常量)。因此,发送和接收操作的另一种表示法是先指定消息类型,后跟1对小括号,将传送的消息字段列表括起来,如下所示:
qname!expr1(expr2,expr3)
qname?var1(var2,var3)
有些时候,接收操作的参数也可能是常量,如下所示。在这种情况下,一个消息接收操作可以执行还要求通道中待接收消息响应字段的值必须与相应的常量值相等。
qname?cons1,var2,cons2
下面的例子中定义了两个进程和两个通道qname和qforb
proctype A(chan q1)
{ chan q2;
q1?q2;
q2!123
}
proctype B(chan qforb)
{ int x;
qforb?x;
printf("x = %d\n", x)
}
init {
chan qname = [1] of { chan };
chan qforb = [1] of { int };
run A(qname);
run B(qforb);
qname!qforb
}
- 同步通信
对于一个同步通道(无缓冲通道),其通道大小为0,因此该通道只能传送数据,而不能存储数据,因此对此类通道,其发送和接收操作必须同步执行。
#define msgtype 33
chan name = [0] of { byte, byte };
proctype A()
{
name!msgtype(124);
name!msgtype(121)
}
proctype B()
{
byte state;
name?msgtype(state)
}
init
{
atomic { run A(); run B() }
}
在上面例子中,通道name是一个全局的同步通道,因此两个进程将同时执行他们的第一条语句,从而实现将124从进程A传递给进程B。进程A的第二条发送语句由于没有匹配的接收操作,因此是不可执行的。
# 5.3 数据定义
- 数据类型
Promela中的基本数据类型有bit、bool、byte、short或int,这些基本类型的位宽分别为 1、1、8、16 和 32。前三个是无符号类型,后两个是有符号类型。除此之外,常用的数据类型还有数组和用户自定义结构体等。Promela中没有浮点数。
| Promela数据类型 | 等价的C类型 | 取值范围 |
|---|---|---|
| bit or bool | 位 | 0..1 |
| byte | Uchar | 0..255 |
| short | Short | -(215-1)..(215-1) |
| int | int | -(231-1)..(231-1) |
2.变量
类似于C语言的变量定义,Promela中的变量必须先定义再使用,变量定义方式如下所示:
<类型描述符> <变量表>
例:
int a, b = 3;
bool x, y;
初始值(如果指定)必须是常量。默认情况下,变量初始化为0。
- 常量
常量是表示十进制整数的数字序列。常用的常量定义方法是使用C风格的宏定义,例:
#define NAME 5
- 数组
数组变量的定义与C语言类似,如下所示。数组索引从 0 开始,因此,在下面的数组中,最大的索引是 3。
int name[4];
与C中一样,数组可以有一个常量作为初始值,初始化所有数组元素。
- 枚举类型
枚举类型可以声明为:mtype = {OK, READY, ACK}
mtype是一个关键字,只允许定义一个mtype枚举类型,且该类型定义是全局的,最多可以声明256个符号常量;mtype变量宽度为8位。该类型的变量可以声明为:mtype Status = OK
- 结构体
用户定义的数据类型可以通过typedef定义:
typedef Msg {
byte a[3], b;
chan p;
}
该类型可以在变量声明中使用,更一般地,可以在任何需要的地方使用:
Msg foo;
chan stream = [0] of {mtype,Msg}
结构体成员的访问方式与C相同,如:foo.a[1]
- 特殊变量
Promela中有两个特殊变量_pid和_last。_pid是一个预定义的局部变量,用于保存进程实例的实例化编号。_last是一个预定义的全局变量,它保存在当前执行序列中执行最后一步的进程实例的编号。初始时,_last为零。
- 关键字
在promela中,以下标识符用作保留关键字
active assert atomic bit
bool break byte chan
d_step D_proctype do else
empty enabled fi full
goto hidden if init
int len mtype nempty
never nfull od of
pc_value printf priority proctype
provided run short skip
timeout typedef unless unsigned
xr xs
# 5.4 语句
- 注释:注释以/*开始,以*/结束。注释不能嵌套。
- 表达式
以下运算符和函数可用于构建表达式:
+ - * / % >
>= < <= == != !
& || && | ~ >>
<< ^ ++ --
len() empty() nempty() nfull() full()
run eval() enabled() pc_value()
大多数运算符都是二元的,其中逻辑否(!)和减号(-)运算符可以是一元和二元运算符,具体取决于上下文。++和--运算符是一元后缀运算符,就像它们在C中定义的一样。异或用运算符^。倒数第二行的函数是一元的,仅适用于消息通道;len函数返回一个已有通道中的消息数量;其他通道算子的含义跟函数名字表达的预期意义是一致的,主要用于辅助偏序规约。这些函数不能用于更大的表达式。例如,!empty(q)将导致语法错误,应使用nempty(q)代替。最后一行的一元函数很特殊。第一个运算符用于进程实例化,执行时,返回它创建的实例编号。前四行的操作符与在C中的定义是相似的。Promela遵循C的约定,即布尔常量的false对应于值 0;任何非零值都表示true。
- 条件表达式
(expr1 -> expr2 : expr3):如果expr1成立,则返回expr2,否则返回expr3。注意->在这里是必须的,不能用;代替。
- 语句
以下可以用作语句:
declaration expression assignment assert
send receive selection else
repetition break goto skip
atomic timeout unless d_step
语句由分号(;)或等效的箭头(->)分隔。->有时表示连续语句之间的蕴含关系,也用于在选择和重复语句中将条件语句和它所保护的语句分开。没有更小的语句作为组成部分的语句称为基本语句。例如,赋值是基本语句,而选择不是。
- 语句的可执行性
语句要么可执行要么被阻塞。在上面列出的语句中,declarations、assignments、assert、goto、break和skip语句始终可执行。对expression,该expression可执行当且仅当其计算结果非零。对send和receive,该语句可执行当且仅当具备send和receive的条件。例如send要求相应的存储通道没有满,receive要求相应的存储通道不为空,同步通信要求send和receive同时成立。对selection和repetition语句,要求其所有选项中至少有一个可执行。如果语句被阻塞,则程序执行到该点时将暂停,直到该语句可执行。
例:相比于写一个繁忙的等待循环while(a != b) skip ,在Promela中使用(a == b)语句可以实现相同的效果。
- 断言
assert(expression):如果expression返回false,则中止程序;否则继续执行。
- 原子块
atomic{statements}
原子块语句在执行过程中不能被其他进程打断。将局部计算原子化可以显著降低验证的复杂性。在其执行期间,只能通过goto语句或者当其语句被阻塞时才会跳转到原子语句的范围之外。如果该语句随后再次变为可执行状态,则可以在该点继续执行。由run语句激活的进程实例的主体被认为在执行激活的原子语句的范围之外。
- Skip语句
空语句,主要用于满足句法要求。
- Timeout语句
当系统中所有其他语句都被阻塞时,就会使能timeout语句。执行时没有效果。
- Unless语句
{statements1} unless {statements2}
从statements1开始执行,在执行statements1中检查statements2是否使能,如果是,则中止statements1的执行并将控制转移到statements2;否则继续执行statements1。如果statements1终止,则statements2被忽略。
在unless中,d_step与atomic相比,被认为是不可分割的;即,如果statements1中的控制位于d_step的范围内,则不会检查statements2的启用性。
- 确定性步骤
d_step{statements}
与atomic具有相同的效果,但效率更高。但是,其范围内的statements必须是完全确定的;它们可能不会跳转到d_step范围之外的标签;可能没有从外部跳转到其范围内的标签;不允许远程引用。最后,第一个以外的语句可能不会阻塞。如果其第一个语句被启用,则整个d_step被启用。Promela认为d_step前面的位置在其范围内,而在其最后一条语句之后的位置则不在其范围内。
如:下面的代码达不到预期效果
goto label;
...
label:
d_step {
...
do
...
break
...
od
}
正确的代码是:
goto label;
...
label: skip;
d_step {
...
do
...
break
...
od; skip
}
# 5.5 控制语句
- 选择
if
:: statements
...
:: statements
fi
一条选择语句中可能会包含多个选项,每个选项都以::开头。选择语句将从其所有选项中选择一个可执行的选项执行。一个选项可以被选择执行要求其第一条语句是使能的。如果有多个选项可供选择,则随机选择一个选项执行。在选择和重复语句中通常用->符号将条件语句和它所保护的语句分开。此时,->符号仅仅是起到分隔的作用。若所有选项都不可执行,则该选择语句会阻塞,直到至少有一个可选择的分支。Else语句可以在selection和repetition语句中使用,并在所有其他条件都不成立是使能。
例:
if
:: (a != b) -> option1
:: (a == b) -> option2
fi
- 循环
do
:: statements
...
:: statements
od
类似于选择,循环语句也包含多个选项,该语句重复选择其中的可执行选项执行,直到通过goto或break显式跳转到语句之外。break将最里层的重复语句,并且不能在重复之外使用。
- 无条件跳转
- 标签:同C语言的标签,标签是后面跟冒号(:)的标识符。任何语句都可以被标记。
- Goto语句:
goto label将控制转移到label标记的语句,该语句必须在与goto相同的过程中发生。
# 5.6 执行Promela系统
Promela系统的系统状态包括全局变量的值、通道缓冲区的内容,以及每个进程实例的位置计数器、局部变量和局部通道缓冲区的值。如果存在never claim,则还包括never claim的位置计数器的值。
初始时,所有未初始化全局变量的值都为0,所有通道缓冲区为空。系统进程实例包括通过proctype上的active修饰符创建的进程,以及init和never进程(如果存在)。这些进程实例的位置计数器位于它们的第一个语句处。
Promela系统的系统状态唯一标识每个(活动)进程实例中使能的语句。一个不包含never claim的系统通过任意选择执行一条使能的语句来执行一步,然后进入一个新的系统状态。因此,进程是异步执行的。但是,如果所选语句是无缓冲的发送(接收),则需要同时执行相应的接收(发送)语句。
如果系统包含一个 never claim,则一个执行步骤是一个组合的、同步的步骤:从 never 声明中执行一条(使能的)语句,并执行系统其余部分的一个步骤。因此,在never claim没有语句使能的情况下(在当前状态下),never claim会阻塞系统的执行。
Promela系统的执行序列或行为是一条执行步骤的最大(可能无限)序列,其中第一个不走取自初始系统状态。
- Atomic语句和d_step语句
atomic语句和d_step限制系统执行其他地方的语句,因为它们(原则上)作为单个基本语句执行。因此,在存在never claim的情况下,系统的执行步骤将 never claim中的单个步骤与atomic语句或d_step的执行序列相结合。
- 分析
可以对Promela系统进行精确(但有效)分析是否存在正确性违反:即,是否存在通过断言中止的执行序列;该序列以无效的结束状态结束;以及是否存在满足通过never-claims定义的线性时序逻辑规约。
- 结束状态
有效结束状态:每个进程都已到达其程序主体的末尾或者进入带有前缀end开头的标签语句处的系统状态。
无效的最终状态:除有效结束状态之外的状态。
严格来说,有效的最终状态也应该要求通道是空的。可通过Spin的-q选项要求最终状态时所有通道都是空的。
